中兴Geek暨英特尔Atom Z2580处理器评测_手机技巧
Atom Z2580的测试前言
在一年之前笔者使用联想K800作为测试平台,对英特尔的Atom Z2460移动处理器作了详细评测,整体得出了性能差、兼容性和效率也存在问题的负面结论,当然敢于面对英特尔和联想发表这样的负面结论是需要勇气的,同时也需要顶住各方面的压力,但笔者我凭借媒体人仅有的节操坚持了原有结论和观点。在这一年的时间里,市场做出了选择,英特尔在移动市场并未有什么斩获,证明了我之前评测结论正确。
也可能是由于对Z2460和K800的评价过于负面,使得今年K900退出后,联想和蓝标的PR姐姐一直都不敢给我送测K900,怕万一又得出负面的结论不好给上面交差,使得我一直都没有拿到K900,也让我Z2580评测处于停工状态,直到我收到中兴的GEEK才使得我这篇评测得以继续,不至于夭折。虽然这样的波折使得我评测晚上不少,但终究迟到总比不来的好。
当然,我们需要用发展的眼光来看待问题,虽然笔者不认同上一代的Medfield是成功的产品,但并不认为Atom后继产品也依然不会有前途,反而从英特尔的Roadmap上则可以看见一片光明,这正是通往胜利的康庄大道。
虽然从产品角度说Medfield的确失败,但其却在英特尔的移动产品线布局上却有重要意义,相比第一代的Moorestown,其整合了芯片和南桥,使得实现了System On Chip的片上化,为Atom的后继发展奠定了坚实的基础。
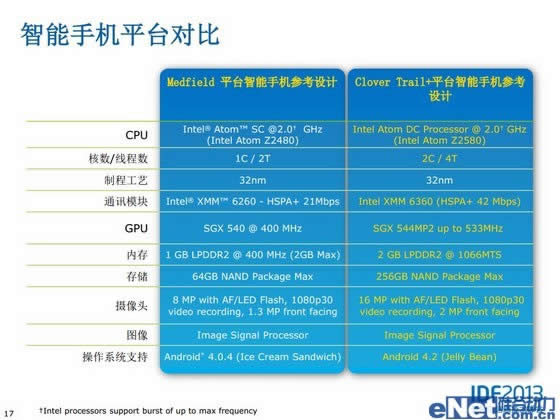
去年推出的Medfield在规格上过于保守,仅为单核心,面对一票ARM的四核自然力不从心,而今年的Clover Trail+则将核心数翻番,而同期ARM在核心数量上并未提升,因此现在Atom同ARM之间的规模差距缩小了,当然除此之外,Clover Trail+在CPU部分的整体架构方面,相比Medfield没有太大改变,在资源规模上类似,也不支持OOO乱序执行,而其竞争对手ARM的早在Cortex-A9就已经支持乱序执行,Atom在这方面吃亏不少。不过Clover Trail+在支持内存容量和带宽上提升很大,这大大加强了处理器的数据吞吐能力,对于提升处理器的性能也应该是立竿见影的。
Z2580 CPU性能测试和分析
在之前的Medfield的评测中,我们着重分析了x86的atom运行NDK应用的兼容性和效能问题,得出的结论是,Atom通ARM的差距不仅仅是在绝对性能上,而更多 在兼容性上,并且在通过二进制代码转换器通过模拟方式运行ARM指令的NDK程序在效能上也很差,整体这部分是偏负面的结论。
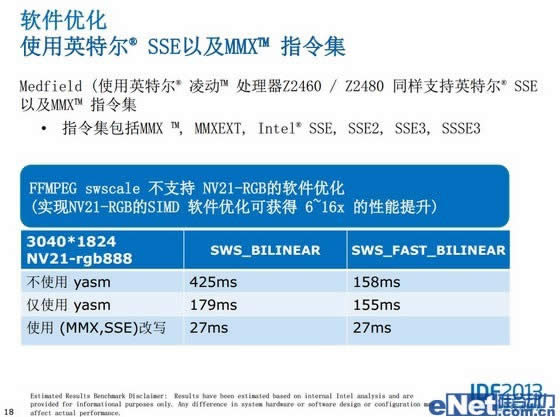
而Z2580同样采用中间件的二进制代码转换器进行模拟计算,在硬件架构上并没什么变化,但我们需要知道的是,英特尔除了是一家硬件公司,还是一家软件公司,为了使得更多厂商推出支持x86指令集的原生应用,提供了x86的Android NDK YASM编译器,使得开发商在开发原生应用时,在花费成本和时间不多的情况下可以方便的编译出兼容x86的应用,使得有更多的原生应用支持x86,就如目前Epic和EA这样的大型公司的游戏产品,如最新的极品飞车,都开始支持x86的NDK,用户在Play下载应用的时候会依据设备类型自动选择下载对应版本,相比一年前Atom应用兼容性相比以前已经好了很多。
具体的处理器性能测试,我们采用XDA大神Chainfire的CF-bench进行,并且CF-bench刚刚升级1.3,提供了对x86原生支持。
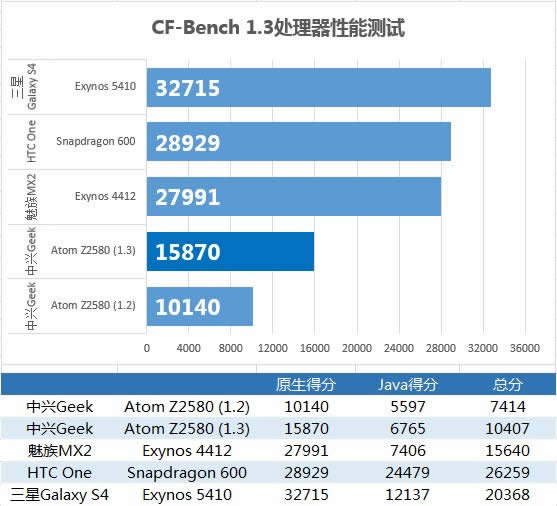
得益于高频,Z2580得单线程性能十分出色,但还是归咎于核心数量少,双拳难敌四掌,Z2580的多线程性能还是不如ARM的竞争者。另外我们分别测试了CF-Bench 1.2和1.3,其中1.2为二进制转换器模拟执行性能,1.3为x86原生代码性能,通过原生得分计算,二进制转换器的执行效率大概为原生代码效率的64%。
Z2580 GPU性能测试和分析
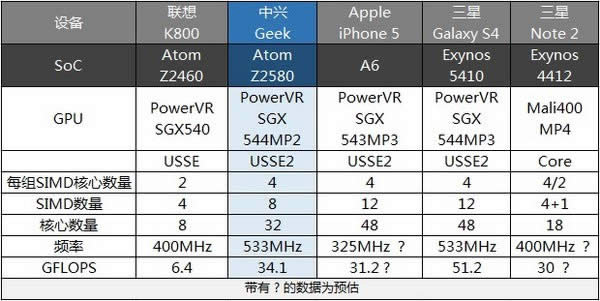
Medfield落后的不仅是CPU性能,还有GPU,其在GPU的配备上过于保守,在2012年仅配备Power VR SGX540,这仅仅停留在竞争对手2010的配置水平(如三星的i9000采用的蜂鸟处理器)。而在Z2580的研发中英特尔的团队就吸取之前的教训,为其配备性能十分主流级的Power VR SGX544MP2,iPhone 5的A6内置的GPU是SGX543MP3,SGX544MP和543MP在性能上基本一致,就是说Z2580的GPU规模是A6 SGX543MP3的2/3,但得益于英特尔自身的工艺优势,使得其GPU频率可以达到533MHz,远远高于A6的325MHz的水平,使得Z2580的GPU理论性能还要略微优于A6。如果再将Z2680内置的SGX544MP4同一年前上代的Z2580的SGX540的理论运算性能相比,34.1GFlops相比6.4GFlops性能提升到了原来的5倍,这个性能提升幅度远远超过摩尔定律预言的趋势。
再来看看实际性能测试,具体的性能测试我们采用GFXbench 2.7的Egypt场景进行测试,Egypt为OpenGL ES 2.0场景,其加入了更为复杂的着色器特效/动态光照和粒子系统/动态水面/法线贴图,相比之前的2.1,画质和硬件需求都大幅提升。GFXbench 2.7测试我们主要考核2个项目,分别为Egypt HD 和Egypt HD - Offscreen (1080p)。Egypt HD为设备原始分辨率运行,能够反映设备实际运行性能,而Egypt HD - Offscreen (1080p)则统一为1080P分辨率,并且并没有强制垂直同步刷新60FPS的性能限制,合适横向比较不同设备的极限能力。
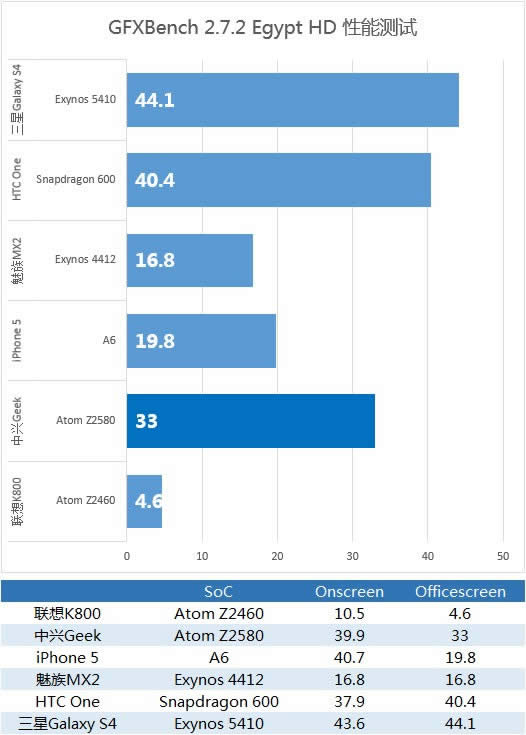
GLbenchmark在2.5之后提供了对x86的原生支持, Z2560可以用A6理论性能的110%达成iPhone 5的150%,整体效能很高。面对搭载SGX540的Z2460性能提升幅度更是在五倍之上。
三星Exynos 5410内置的SGX544MP3和Z2580的SGX544MP2,同频都为533MHz,但规模要大上50%,性能领先Z2580也属正常,但三星Exynos 5410相对性能优势并不到50%,而仅为33%,这很大程度还是与高温状态的频率稳定性有关系。
同样也是由于GPU规模差距,Z2580内置的SGX543MP2面对高通APQ8064内置的Adeno 320之类,其在性能上还是存在明显差距,但竞争对手这样的性能优势是在牺牲功耗,通过不切实际的堆砌规模而获得的(16个SIMD 4D实在太夸张),相对Z2580选择533MHz的SGX544MP2来说,这毫无疑问是在性能和功耗之间选择了一个十分微妙的平衡点。

英特尔的IDF2013的PPT相比其竞争对手过于厚道和保守,仅仅说是2倍的CPU性能和3倍的GPU性能,经过我们分析和测试,实际是前一代性能的3和6倍,当然,这在很大程度上并不是因为Z2580有多强,而是因为之前的Z2460实在是太烂了。
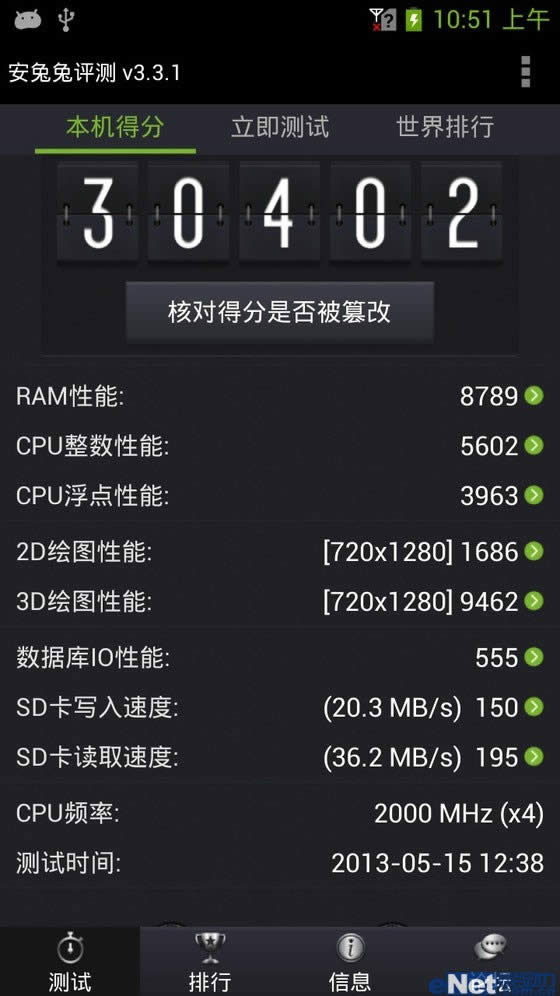
虽然我一直不鼓励用安兔兔性能测试作为衡量标准,但很多人关心这个分数,我海思加上这个环节,Z2580的得分为30402,几乎逼近Snapdragon 800。我们分析高分的原因在于两个方面,第一个是内存得分,Geek高达8789,这个得分远远高于Snapdragon 600和A15平台,也高于Snapdragon 800,同时这部分得分在总分加权比例偏高,使得Z2580的得分高;另外一方面,3D性能在安兔兔中的比例很高,但安兔兔的3D性能测试,并为像GFXBench和3Dmark那样统一分辨率,而实用设备实际分辨率,相比Geek GPU更强大的设备基本都采用1080P分辨率,过高的分辨率反而拖累了3D部分的得分,720P低分辨率的Geek反而可以占不小便宜。从上2点就可以看出安兔兔在得分算法上存在很大问题,实际上30402的高分并不能代表Geek真实的性能表现和体验,这也是很大程度我们并不鼓励将安兔兔这个不靠谱软件作为衡量手机性能标准的原因。
Z2580频率稳定性/温度测试
在这个测试开始之前,需要做点简单的科普。手机处理器标识一个频率,如四核1.6GHz,并不是永远都稳定运行在1.6GHz,而会依据任务负载和温度进行调节,如待机的时候仅为200MHz,在视频播放时候则为600MHz,满载时才运行在1.6GHz。
Z2580在频率控制上也不例外,其进一步改善了电源管理,引入Burst Performance技术,将设备分为C6待机模式、LFM低频模式、HFM高频模式和最高频率模式,在电源管理方案方面有十分高的弹性。我们具体测试也是如此,中兴Geek我们没插SIM卡丢单位一整个周末,电量仅仅下降6%,这说明其在待机状态下功耗控制十分出色。当然,对于现在的智能手机SoC,在待机时候,可以通过降低频率和电压来降低SoC功耗以提升续航,这对于智能手机并不是大问题,真正的问题在于高负载的功耗和性能表现。
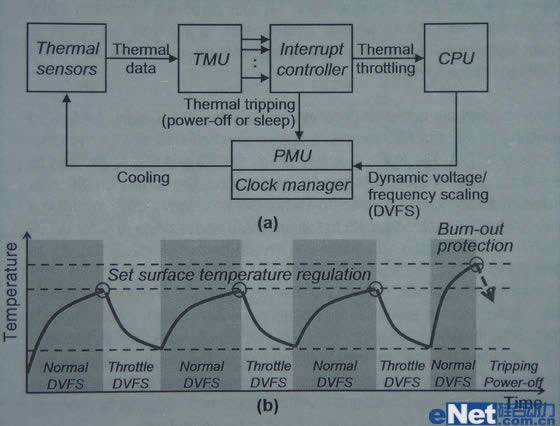
在高负载时候,也不是一直运行在最高的满频,而会有个温度阀值,当温度到达设定的温度则会强行降频,在降频后,温度下来又会重新提高频率,之后不停的这样反复。这样的系统在三星或者NVIDIA的系统里叫DVFS.以三星Exynos 4412处理器为例,其内置温度传感器,将检测SoC温度传递给TMU热功耗控制单元,如果温度过高,通过高优先级的中断控制器控制电源管理器的时钟控制器和CPU降频,保证系统温度在合适范围,如果温度过高还会强行关闭系统,保证系统安全。的DVFS(动态电压和频率缩放控制)可以单独调节CPU核心、L2缓存、GPU、内存接口和其他外围电路的电压和频率。
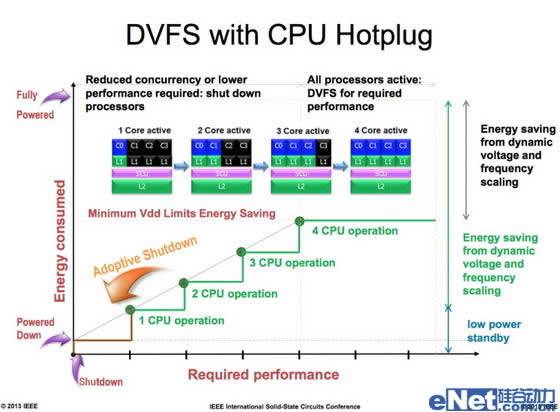
当然,如果是Exynos 5410这样的处理器这个系统还会更为复杂,因为Exynos 5410为big.LITTLE A15+A7混合结构,系统除了频率调节,还会动态切换A15和A7的大小核心的工作状态。
我们这部分具体测试方法如下,我们使用Stablity Test 2.7的Classic Stablity Test来进行CPU负载,使得处理器一直处于满载(GPU为空载)。使用Android Tuner来进行频率和温度的监测。
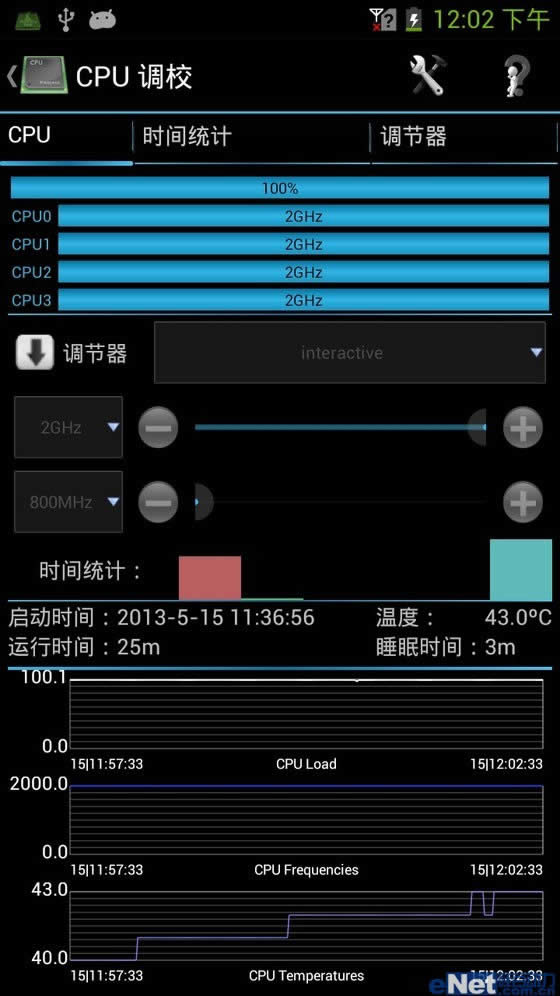
英特尔Z2580测试。Z2580桌面待机31度,基本和空调房的室温一样,而在CPU满载测试10分钟后,其频率依然可以完全稳定2GHz不动摇,在频率稳定性上十分好,并且其核心温度最高仅为43度。
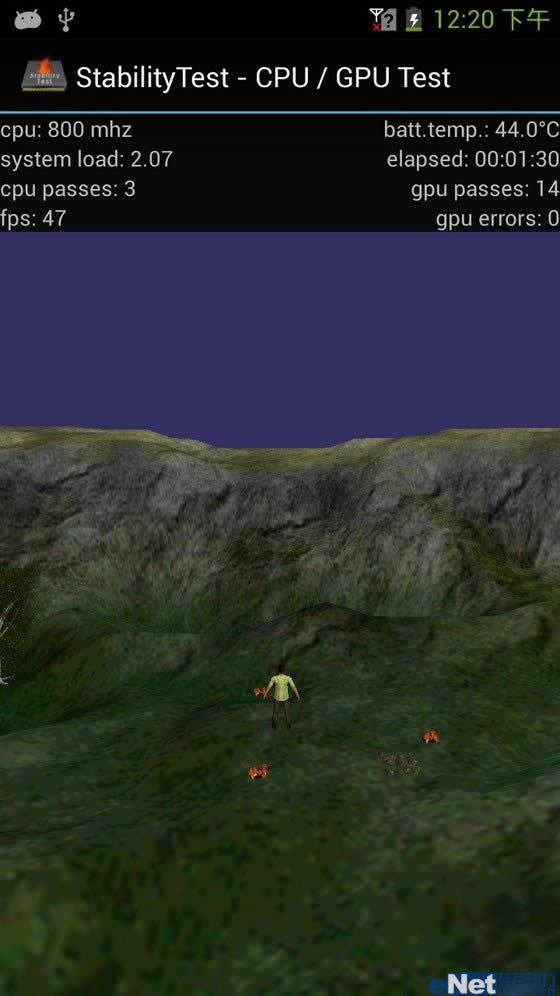
而使用CPU+GPU同时满载测试,Z2580 CPU频率会在800-2GHz之间跳动,这是由于CPU和GPU共享TDP上限,原来3W的热功耗仅由CPU发出,而现在GPU占用了很大部分的TDP,而CPU只能降频,这样才能使得SoC整体功耗在TDP允许的范围之内。在CPU+GPU同时满载,SoC的温度也更高,达到了46度。
而相比ARM架构的Exynos 5410和Snapdragon 600,我们的测试期在温度和频率稳定性上要差上很多,特别是A15架构的Exynos 5410,温度动辄上到90度,并且频率十分不稳定,在稍长时间运行频率就会降到600MHz水平,虽然A15架构得理论性能更高,但在高温降频情况下,这个实际性能是要大打折扣的,而Atom Z2580则可以一直稳定运行在2GHz,并且温度更低。Z2580的TDP在3W水平,而Exynos 5410和Snapdragon 600官方并没正式公布其TDP,但笔者估计这两者的实际功耗以及到达8-10W的水平,ARM处理器一直以来最具优势的低功耗、低温的优势现在面对Atom已经不复存在了。
更多ARM处理器对比测试可以参看:主流手机4核处理器频率稳定性测试http://www.enet.com.cn/article/2013/0628/A20130628293815.shtml
外围:基带和ISP
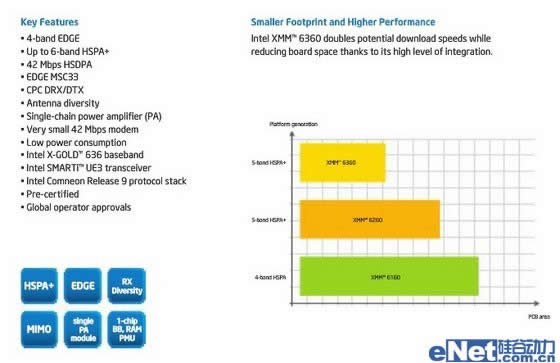
除开核心性能部件,我们也许有更为关注Clover Trail+的外围,首先来说说基带和Modem,在基带方面Z2580用XMM 6360取代旧有的XMM6260,XMM6360增加了对3GPP release 9的支持,使得其可以实现42Mbps的DC-HSPA+(Category 24)速率。对于英飞凌的收购使得英特尔在移动通讯领域没有明显的短板,当然目前英飞凌基带在同高通的基带对比还是存在一定的差距,特别是在核心专利方面,XMM6360并未提供对于CDMA2000和4G LTE网络的支持。

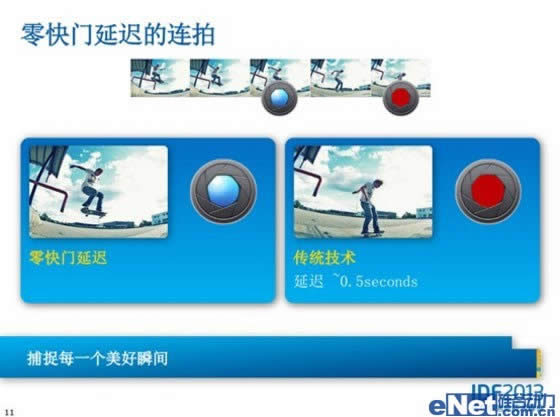
Clover Trail+内部集成的ISP图像信号处理器和Medfield一样,但得益于收购的Silicon Hive技术,其在固件方面有很大改进,在连拍、HDR等方面的性能和功能有明显提升,并且减少了快门延迟。
展望2014 x86的彻底反攻年

下次世代的Bay Trail,虽然这个研发代号很悲催,但确前途无量。上时代的单核Medfield不足以抗衡ARM四核不足为奇,而本世代的双核Clover trail+处理器性能及可以同四核的ARM A15处理器媲美,我们需要记住的是,这个2013年的Clover trail+仅仅是使用英特尔2008年的老Atom架构+2010年的32nm工艺,就可以在性能方面威胁到ARM处理器的领先地位。那2013/2014的全新Atom会带来什么?
今年的Clover Trail+相比去年的Medfield在架构上和工艺上都没有升级,而明年Q1的Bay Trail则是在架构和工艺上都有天翻复地的变化,虽然这有悖英特尔传统的Tick-Tock工艺架构交替升级的策略,但我们不得不说这样的升级很给力。下面我们将从架构和工艺两个方面对下世代的Bay Trail进行初步展望。
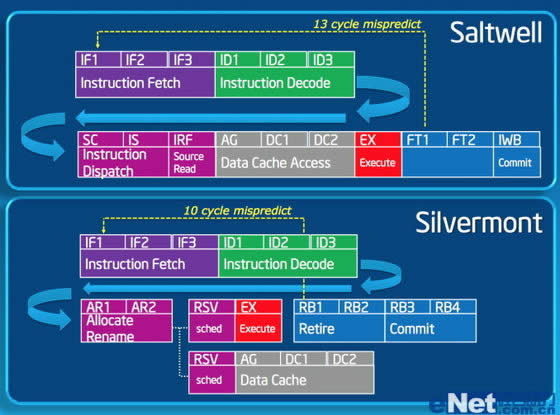
次世代的Atom则将采用全新的Silvermont微架构, Silvermont微架构最为核心的变化为支持Out Of Order乱序执行。之前Bonnell是16级顺序执行流水线,由于是顺序执行,即使是那些不需要访问缓存的指令,即使什么都不干,也必须经过这些缓存访问的流水线级别,使得指令集的流水线级别过长,大大降低了效率,而新的Silvermont微架构允许不需要从内存获得数据的指令跳过一些级别,将流水线级别从13缩到10级。除了乱序执行和流水线优化,Silvermont还改进了分支预测的算法,得益于降低分支预测的失误率,能够使得单周期执行指令数IPC相比Bonnell提升5-10%。
顺序执行到乱序执行的改进并不是什么值得炫耀的,ARM在Cortex-A9就已经支持,不过反过来想,Atom不用支持乱序执行,效能就优于ARM,之后Silvermont支持乱序执行了,这样可提升余地很大,而已经支持乱序执行的ARM就没有这个提升余地了。
除了架构上改进,Silvermont在规模上也将为物理四核,这样综合效率和规模双方面的提升使得其性能大幅提升,按照英特尔的描述,Silvermont性能是现有产品的三倍。
反观ARM路线图上的Cortex-A15和A50架构,为了追逐性能使得其在规模上已经过大,导致功耗过高,不仅在核心规模上已经没有提升的余地(不能再从4核变成真8核),并且丧失以往ARM的绝对低功耗的优势,虽然ARM想出了big.LITTLE 大小核心的奇淫技巧,但这并不能阻止功耗优势天平倾向英特尔。
工艺和功耗墙
说到功耗,就不得不说工艺,想要在可以接受的功耗情况下,扩大芯片规模,就必须依靠工艺的进步来缩小芯片面积和降低漏电率。而工艺方面这一直是英特尔的传统优势领域,现在英特尔Atom运用的32nm HKMG对于英特尔而言仅仅是几年前的老工艺,相比TMSC LP 28nm和三星28nm HKMG在线宽上要落后半代,但即使如此,其在漏电率和频率方面却依然占优(从前面的频率稳定性和温度测试就可以看出),这充分体现出英特尔在工艺方面的领先优势。并且英特尔在Bay Trail则将升级到和Ive Bridge一样代数的22mm新三栅极鳍状物工艺。

但Atom使用的22nm 3D晶体管工艺和Ive Bridge的工艺还是存在一些差别,Ive Bridge使用的工艺是P1270,而低功耗SoC使用的是P1271。迁移到22nm 3D晶体管,如果能够使得在相同的漏电水平让阈值电压下降100 mV,我们需要记住的是功耗是电压的平方(如果你学过初中物理),100mV的降低这个提升是十分巨大的,单纯在电压降低方面就可以使得功耗降低25-35%。
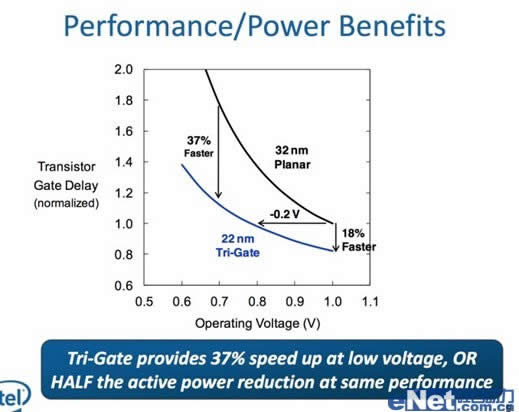
以上仅仅是理论计算,实际上Atom得益于新工艺,可以让阈值电压下降0.2V,到0.7V水平,使得在相同电压性能能够获得37%的提升,或者仅需一半功耗就能维持原有性能。这样的升级无疑给力的多。并且在桌面CPU这个工艺早已驾轻就熟,上到Atom也不会有什么问题,英特尔是值得信赖的。
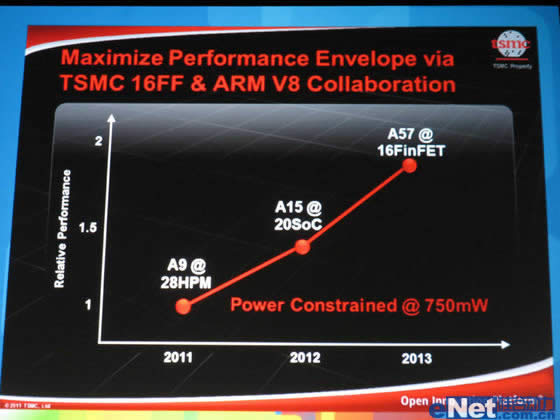
再反观ARM,按照台积电之前计划的时间节点,20nm HPm应该在2011年量产,但现实是直到2013年4月的今天,台积电的20nm HPm产品(Snapdragon 800)和20nm HPl(Tegra 4)依然不见踪迹。可见TMSC的进度严重滞后。台积电计划在今年年底将20nm作为过渡工艺,明年直接跨越到16 FinFET。
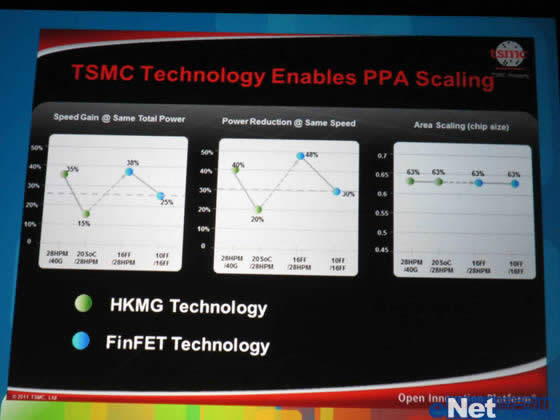
但这个作为过渡的20nm工艺相比现在并未完全量产的28nm HPm,在相同功耗情况下性能提升15%,而在相同性能情况功耗则可以下降20%,这样的提升幅度要远低于TMSC工艺升级一般性能提升25%、功耗降低30%的平均水平,由此看来TMSC的20nm工艺升级较为不给力。而所谓的16 FinFET原来计划2015年,现在却被硬提到2014,明显更为不靠谱。
受到影响的不仅只有时间节点,GPU也受到牵连,Power VR 6由于卫星放得太高,使得其无法再现有28nm工艺,甚至下代20nm工艺上实现,需要等到台积电的16nm FinFET工艺,但台积电的16nm FinFET工艺看来需要等到2015年,就是说单纯依靠Power VR SoC的GPU性能在短时间内很难提升(除非SGX554MP8大丈夫?),因此英特尔在明年的Atom中放弃了PowerVR架构,而改用和PC相同的HD Graphics,但将完整的HD4000塞入手机并不现实也无必要,因此其仅为HD4000 16 EU 1/4的规模,4个EU,并且其频率也应该低于Ive Bridge,整体性能应该在HD4000的20%左右。再加上HD的构架更多考虑的是Shader Model 3.0甚至4.0的特性,面对现在主流的OpenGL ES 2.0移动应用并不能充分发挥。我们对Silvermont的图形性能究竟如何,所以还是要打上问号的。
前途无量的Atom 顺我者昌
明年Q1 22nm Bay Trail推出的时候,Atom支持OOO乱序执行、由物理双核变成物理四核,GPU由SGX544MP3变为HD Graphics,这样巨大幅度的提升,使得ARM在性能上很难望其项背。并且英特尔加持先进的22nm 3D晶体管工艺,无论是台积电还是三星半导体,在工艺上都很难与英特尔抗衡。因此综上几个原因,英特尔的移动处理器在于ARM处理器的对决中,硬件方面Atom将会彻底占到上风。
当然除了处理器本身的架构和工艺,其外围变化我们也不能忽视,今年IDF更多的提及感知计算的理念,通过更多的内置传感器和软件,英特尔会更进一步的推动人与机器的互动方式。
当然,在互联方面,前面部分我们曾经提及目前英飞凌在基带方面同高通还是存在一定的差距,特别是在核心专利方面,目前Clover Trail+搭配的XMM6360并未提供对于CDMA2000和4G LTE网络的支持。但这个劣势仅仅是现在,英飞凌下一代基带XMM7160则会提供全面的对于LTE的支持,届时待Verzion、中国电信这样的CDMA2000网络运营商也会迁移LTE网络后,英特尔在CDMA2000方面的劣势就可以忽略,相对高通在基带方面差距也会减小。只不过现在对于英特尔而言现在是黎明前最为黑暗的时候,英特尔只要坚持到迁移到LTE就将迎来光明,2014年将是x86载移动领域的彻底反攻年。

再来做个比方,现在的Atom就如一匹身出名门的并未成年的年轻赛马,虽然并不是最快,但也锋芒毕露体现出不凡实力,但在之后必会大有作为。中兴之前在幼年时期(Grand X In)的投入使得其占有英特尔移动处理器设备的先机,因此中兴在前期看似没有回报的投入是英明和富有远见的。
毫无疑问,依据现在的Roadmap看英特尔的Atom移动处理器相比ARM,待到Bay Trail之后其无论是在绝对性能上还是绝对功耗上都更为前途无量,反观ARM后即A15/A50架构在性能上提升余地不大,并且失去功耗的绝对优势,移动设备厂商如果能够更早的迁移到英特尔平台,在未来产品上则会有更强的竞争力,或者夸张点说,如果厂商现在对于Atom视而不见,那这个厂商就是没有未来的,而对于SoC厂商而言,相信ARM和它的小朋友们现在都已经被吓坏了。
……